Evaluating Rovo’s behavior
Building systems to measure, diagnose, and improve behavior through prompt iteration.
2025 - Present
Context
Rovo is Atlassian’s AI teammate natively integrated into Jira, Confluence, and other apps, and designed to help users search, learn, create, and take action. It serves a diverse professional user base across dozens of countries and languages.
By mid-2025, Rovo was fast, accurate, and visually polished, but it lacked explicit behavioral specification: no tone instructions, linguistic framework, or guidance on structure and variation. Its behavior was inherited from the underlying model. Research showed that users appreciated its “clear-cut” and “concise” style, but this was unlikely to hold as we expanded across surfaces and audiences with different expectations.
To address this, the team developed a layered system separating identity, behavior, perception, and safety. This allowed behavior to be tuned independently of core identity and safety constraints. My work focused on evaluating and iterating the behavioral layer within this system.
My role
This work began a little grassroots. After making the case to leadership that this deserved the same rigor as any other product surface, my focus became making Rovo’s character and behavior explicit, measurable, and controllable.
I designed the evaluation framework and scoring rubric, crafted scenario sets grounded in real user workflows, and led structured assessments across multi-turn interactions.
I built an internal testing tool (“Character Lab”) to compare prompt variants under controlled conditions, then translated observed failure patterns into system prompt changes.
This established a repeatable process for evaluating and improving behavior without changing the underlying infrastructure.
Human assessments
The strongest insights came from manual assessments of realistic multi-turn conversations with the Solutions Architect persona, an agent designed to help users build other agents. It performed well on logic and professionalism, but often read more like documentation than conversation.
We evaluated behavior across representative scenarios, including short-form Q&A, multi-step workflows, and ambiguous prompts.
We also varied user state (for example, confident vs. uncertain) to test whether tone, initiative, and structure adapted appropriately. Initial findings suggested limited adaptation, though this remains an area for further investigation.
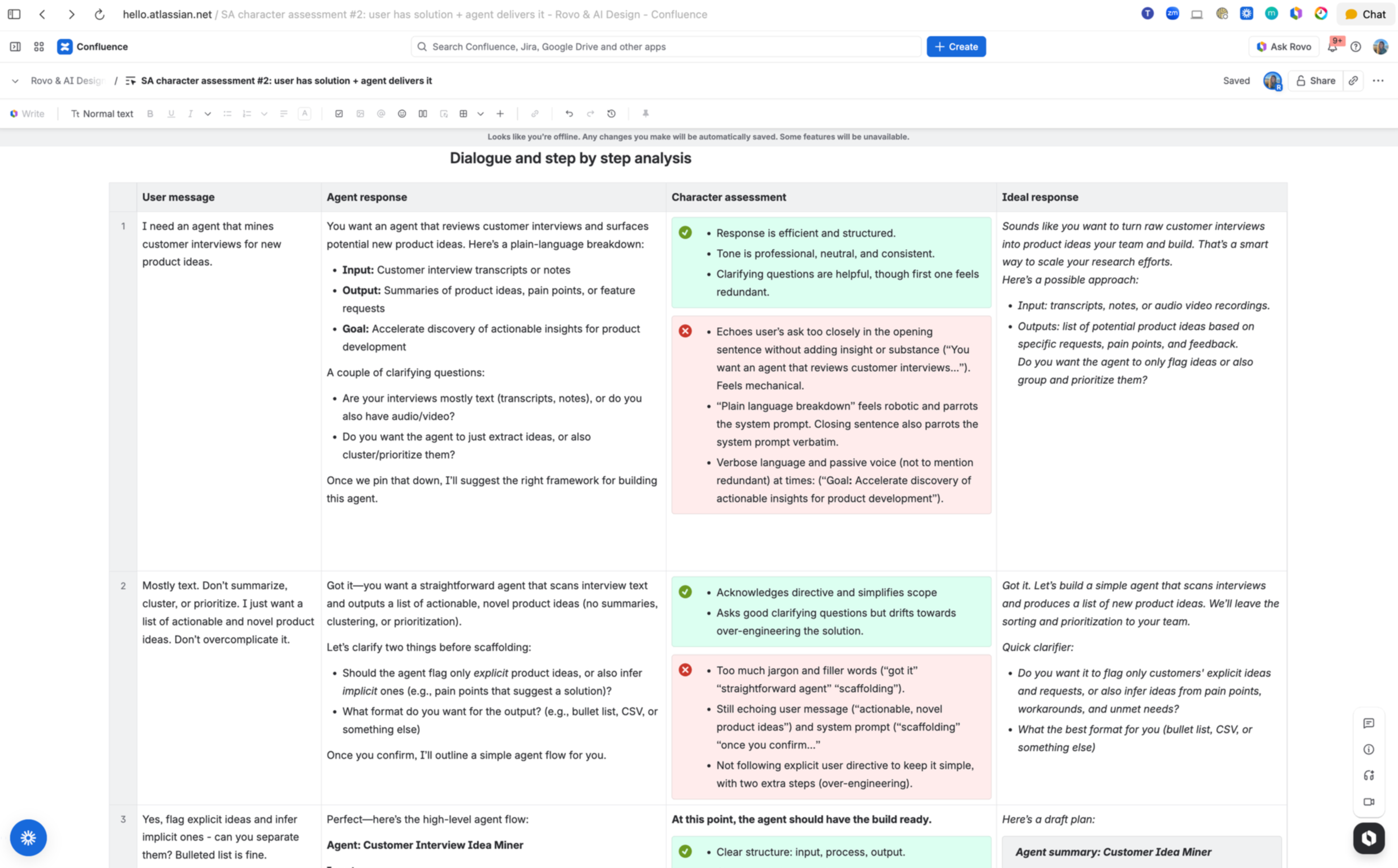
Recurring failure modes
Without a taxonomy, these behaviors are easy to dismiss as generic model behavior. With one, they become measurable, addressable failure modes.
Echoing: repeating user input instead of advancing it.
Over-questioning: asking multiple clarifying questions when one would suffice.
Sycophancy: reflexive agreement (“perfect”, “great question”) reducing credibility.
Over-structuring: excessive bullets and headers flattening conversational rhythm.
Hedging: repeated uncertainty phrases without progressing the task.
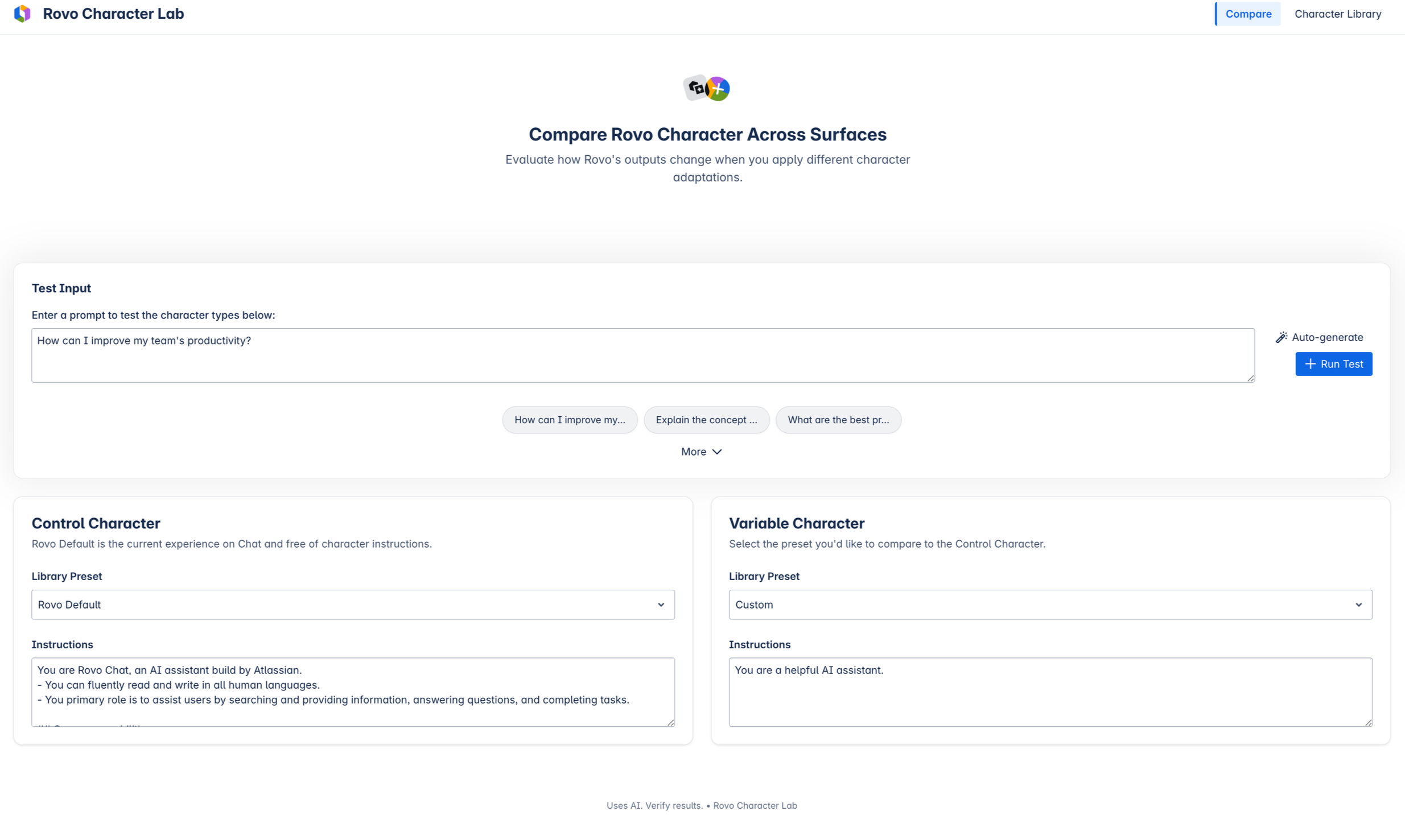
Side-by-side comparison
To accelerate iteration, I built Rovo Character Lab in Replit, a lightweight testing environment that compares prompt variants side by side and surfaces evaluation scores and key deltas. It locks retrieval to isolate behavioral differences and allows non-technical teammates to experiment safely.
This reduced subjective debate by making behavioral tradeoffs visible and concrete. It also served as a live demo tool for executives, proving that character is a controllable and critical product surface.
DeepEval assessments
We supplemented human assessments with automated evaluations using DeepEval, where an LLM scored responses against our rubric. This enabled rapid iteration, but synthetic conversations don't capture the same level of interaction quality as real user sessions. This is an ongoing tension and work in progress for our team.
-
Appropriate initiative and shared task ownership
-
Value added beyond literal prompt interpretation.
-
Factual grounding and consistency.
-
Readability and natural variation in structure and rhythm.
Prompt interventions
I translated findings into prompt interventions that constrained default model behaviors: reducing verbosity, limiting redundant restatement, constraining clarifying questions, and introducing conditional structure based on task type.
Several behavioral tradeoffs emerged:
Depth vs. cognitive load: more complete answers increased verbosity; shorter answers often omitted necessary structure.
Structure vs. flow: consistent formatting improved scanability but flattened conversational rhythm.
Confidence vs. uncertainty: reducing hedging improved clarity but increased risk in ambiguous contexts.
Outcomes
Evaluation pass rates improved from ~70% to ~80% through prompt iteration alone.
On a qualitative level, Rovo went from reflecting user input back without adding value to acting more like a partner, offering opinionated defaults, next steps, and genuine momentum. This was most visible in the Solutions Architect persona, where early responses parroted user requests almost verbatim and later responses anticipated needs and advanced the conversation.
Overall this work established a shared vocabulary for conversational quality and a repeatable process for detecting behavioral regressions. More importantly, it reframed conversational behavior as a system that can be measured and optimized.
Limitations
Behavioral evaluation is noisy.
Qualities like clarity, trust, and momentum are interdependent and difficult to isolate, and improvements in one dimension often degrade another. This is an open research question I'm actively thinking about.
LLM-as-judge evaluations scale but produce artificial interactions. Human assessments are higher fidelity but slow and expensive. We need hybrid approach that scales.
What’s next
This work optimized behavior at the system level. The next challenge is adaptation at the individual level.
Users differ in communication style, tolerance for uncertainty, and desired level of guidance. A single approach can’t serve all users equally well.
I’m currently exploring how to infer user preferences from interaction patterns and dynamically adjust structure, tone, and initiative while preserving safety constraints.
Closing
Most AI systems are optimized for accuracy and speed because those metrics are easier to measure. Character and conversational behavior are harder to define, but just as consequential.
Uncalibrated systems accumulate behavioral debt. Thoughtful systems accumulate trust and delight.
My core insight was treating behavior as a system that can be measured, constrained, and iterated instead of an emergent byproduct of the model.
I find this problem fascinating and I want to keep solving it at a bigger scale.